Na Facebook skupině Arduino a Raspberry poradna CZ & SK se objevil dotaz od pana Tesaře.
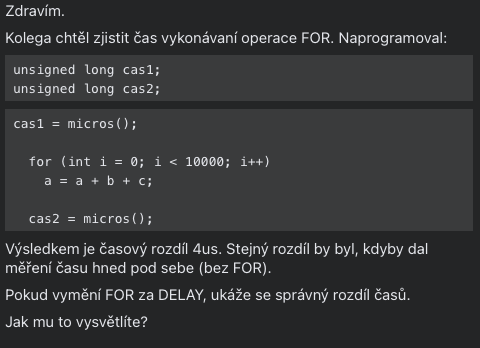
Protože mě zaujal, trochu se k němu rozepíši.
Na začátek je dobré si uvědomit, že kompilátory jsou dnes hodně chytré a když jim to nezakážeme, snaží se za nás udělat kód co nejoptimálnější.
Jsou různé techniky, jak kompilátor k optimalizaci může přistoupit. Nebudu je podrobně rozebírat (protože je sám stejně všechny neznám). Zkusíme se ale podívat, k čemu zřejmě došlo v tomto případě.
Zadání
Původní kód je napsaný pro Arduino a vypadá takto:
int a = Hod1;
int b = Hod2;
int c = Hod3;
unsigned long cas;
unsigned long cas1;
unsigned long cas2;
void setup() {
Serial.begin(9600);
cas1 = micros();
for (int i = 0; i < 10000; i++)
a = a + b + c;
cas2 = micros();
cas = cas2 - cas1;
Serial.print("Čas operácií = ");
Serial.print(cas);
Serial.println(" µs");
Serial.print("čas1 = ");
Serial.println(cas1);
Serial.print("čas2 = ");
Serial.println(cas2);
}
void loop() {
}Zjednodušení kódu
Arduino ekosystém při kompilaci obalí tento kód ještě dalšími příkazy (přidá implementaci funkce main, ve které volá funkce setup a loop atd.). Protože se ale v další části koukneme do assembleru, který kompilátor produkuje, zjednodušil jsem analyzovaný kód na nutné minimum (z mého pohledu). Místo Serial.println je použita funkce printf a místo micros je použita funkce time. K tomuto kroku jsem přistoupil, abych se zbavil nutnosti vkládat závislosti Arduino ekosystému.
#include <stdio.h>
#include <time.h>
time_t cas1;
time_t cas2;
int a = 1, b = 2, c = 3;
int main() {
cas1 = time(NULL);
for (int i = 0; i < 10000; i++) {
a = a + b + c;
}
cas2 = time(NULL);
printf("%d\n", a);
}
Tento program jsem uložil do souboru main.c.
Překlad kódu
Arduino projekty pro klasické desky založené na AVR procesorech (Uno, Mega, …) se kompilují pomocí avr-gcc (resp. avr-g++) kompilátoru.
Základní příkaz pro kompilaci souboru main.c je avr-gcc main.c. Kromě toho je ale možné funkci kompilátoru konfigurovat pomocí tzv. přepínačů.
Nás budou zajímat přepínače -Ox, který slouží k nastavení úrovně optimalizace a také přepínač -S, díky kterému bude kompilátor produkovat assembler. Ten budeme dále analyzovat.
Vypnutí optimalizací
Začneme tím, že se podíváme, jaký kód překladač produkuje při vypnuté optimalizaci. Assembler může vypadat děsivě, ale není potřeba rozumět všemu. Důležité části okomentuji.
Pro význam jednotlivých instrukcí je možné nahlédnout do dokumentace instrukčního setu AVR.
Takto vypadá Assembler při volání avr-gcc -mmcu=atmega328p -O0 -S main.c
Použitá ATMEGA328p je 8-bit mikrokontrolér, takže použité registry jsou 8bit. Když tedy chceme pracovat s 16bit hodnotou (int), musíme použít dva registry – viz např. řádky 66 a dále.
.file "main.c"
__SP_H__ = 0x3e
__SP_L__ = 0x3d
__SREG__ = 0x3f
__tmp_reg__ = 0
__zero_reg__ = 1
.text
.comm cas1,4,1
.comm cas2,4,1
.global a <-- od této části dále je vytvoření prostoru v paměti pro proměnné a, b, c
.data
.type a, @object
.size a, 2
a:
.word 1
.global b
.type b, @object
.size b, 2
b:
.word 2
.global c
.type c, @object
.size c, 2
c:
.word 3
.section .rodata
.LC0:
.string "%d %d %d\n"
.text
.global main
.type main, @function
main: <-- zde začíná funkce main
push r28
push r29
in r28,__SP_L__
in r29,__SP_H__
sbiw r28,10
in __tmp_reg__,__SREG__
cli
out __SP_H__,r29
out __SREG__,__tmp_reg__
out __SP_L__,r28
/* prologue: function */
/* frame size = 10 */
/* stack size = 12 */
.L__stack_usage = 12
ldi r24,0
ldi r25,0
call time <-- volání funkce pro zjištění aktuálního času
std Y+3,r22
std Y+4,r23
std Y+5,r24
std Y+6,r25
ldd r24,Y+3
ldd r25,Y+4
ldd r26,Y+5
ldd r27,Y+6
sts cas1,r24
sts cas1+1,r25
sts cas1+2,r26
sts cas1+3,r27
std Y+2,__zero_reg__ <-- na adresách Y+2 a Y+1 je uložena hodnota čítače (proměnná i)
std Y+1,__zero_reg__
rjmp .L2 <-- skoč na návěstí L2
.L3: <-- zde začíná tělo cyklu for
lds r18,a <-- načti nižší byte proměnné a do registru r18
lds r19,a+1 <-- načti vyšší byte proměnné a do registru r19
lds r24,b <-- načti nižší byte proměnné b do registru r24
lds r25,b+1 <-- načti vyšší byte proměnné b do registru r25
add r18,r24 <-- sečti registry r18 a r24
adc r19,r25 <-- sečti registry r19 a r25, přičti přenos z předchozího sčítání
lds r24,c <-- obdobná situace se opakuje pro proměnnou c
lds r25,c+1
add r24,r18
adc r25,r19
sts a+1,r25 <-- uložení vyššího byte součtu do proměnné a
sts a,r24 <-- uložení nižšího byte součtu do proměnné a
ldd r24,Y+1 <-- do registrů r24 a r25 je uložená hodnota čítače
ldd r25,Y+2
adiw r24,1 <-- k hodnotě čítače přičte 1
std Y+2,r25 <-- uloží novou hodnotu čítače z registrů r24 a r25 na adresu Y+1 a Y+2
std Y+1,r24
.L2:
ldd r24,Y+1 <-- načtení dat pro vyhodnocení podmínky cyklu
ldd r25,Y+2
cpi r24,16 <-- vyhodnocení podmínky cyklu
sbci r25,39
brlt .L3 <-- pokud podmínka platí, skoč na L3, jinak pokračuj dále
ldi r24,0
ldi r25,0
call time <-- volání funkce pro zjištění aktuálního času
std Y+7,r22
std Y+8,r23
std Y+9,r24
std Y+10,r25
ldd r24,Y+7
ldd r25,Y+8
ldd r26,Y+9
ldd r27,Y+10
sts cas2,r24
sts cas2+1,r25
sts cas2+2,r26
sts cas2+3,r27
lds r18,a
lds r19,a+1
lds r20,cas2
lds r21,cas2+1
lds r22,cas2+2
lds r23,cas2+3
lds r24,cas1
lds r25,cas1+1
lds r26,cas1+2
lds r27,cas1+3
mov r30,r19
push r30
push r18
mov r18,r23
push r18
mov r18,r22
push r18
mov r18,r21
push r18
mov r18,r20
push r18
mov r18,r27
push r18
mov r18,r26
push r18
mov r18,r25
push r18
push r24
ldi r24,lo8(.LC0)
ldi r25,hi8(.LC0)
mov r24,r25
push r24
ldi r24,lo8(.LC0)
ldi r25,hi8(.LC0)
push r24
call printf
in r26,__SP_L__
in r27,__SP_H__
adiw r26,12
in __tmp_reg__,__SREG__
cli
out __SP_H__,r29
out __SREG__,__tmp_reg__
out __SP_L__,r28
ldi r24,0
ldi r25,0
/* epilogue start */
adiw r28,10
in __tmp_reg__,__SREG__
cli
out __SP_H__,r29
out __SREG__,__tmp_reg__
out __SP_L__,r28
pop r29
pop r28
ret
.size main, .-main
.ident "GCC: (Homebrew AVR GCC 9.3.0_3) 9.3.0"
.global __do_copy_data
.global __do_clear_bss
Z Assembleru vidíme, že při vypnutých optimalizacích kompilátor “tupě” přeloží kód for cyklu z C do Assembleru.
Se zapnutými optimalizacemi
Jak už jsem psal dříve, kompilátoru je možné říci, jakým způsobem má optimalizovat. Přístupů je celá řada, například:
- -O0 – bez optimalizací
- -Os – optimalizace velikosti výsledného kódu
- -O3 – optimalizace rychlosti
- …
Nyní tedy zkusme kód zkompilovat s přepínačem -Os.
avr-gcc -mmcu=atmega328p -Os -S main.c
V následujícím kódu už není situace tak přehledná, takže část okomentuji v něm a část v odstavcích pod kódem.
.file "main.c"
__SP_H__ = 0x3e
__SP_L__ = 0x3d
__SREG__ = 0x3f
__tmp_reg__ = 0
__zero_reg__ = 1
.text
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "%d %d %d\n"
.section .text.startup,"ax",@progbits
.global main
.type main, @function
main:
/* prologue: function */
/* frame size = 0 */
/* stack size = 0 */
.L__stack_usage = 0
ldi r25,0
ldi r24,0
call time <-- volání funkce pro zjištění aktuálního času
sts cas1,r22
sts cas1+1,r23
sts cas1+2,r24
sts cas1+3,r25
lds r18,b <-- načtení hodnot z proměnných do registrů
lds r19,b+1
lds r20,c
lds r21,c+1
lds r24,a
lds r25,a+1
add r24,r18 <-- posčítá a+b+c do registrů r24 a r25
adc r25,r19
add r24,r20
adc r25,r21
add r18,r20
adc r19,r21
ldi r22,lo8(15) <-- do r22 ulož hodnotu 15
ldi r23,lo8(39) <-- do r23 ulož hodnotu 39
mul r18,r22 <-- r1,r0 = r18 * r22 (součin dvou 8bit hodnot je až 16bit hodnota, výsledek je uložen do registrů R1 a R0)
movw r20,r0 <-- r20 = r0, r21 = r1
mul r18,r23
add r21,r0
mul r19,r22
add r21,r0
clr r1
add r24,r20
adc r25,r21
sts a+1,r25
sts a,r24
ldi r25,0
ldi r24,0
call time <-- volání funkce pro zjištění aktuálního času
sts cas2,r22
sts cas2+1,r23
sts cas2+2,r24
sts cas2+3,r25
lds r18,a+1
push r18
lds r18,a
push r18
push r25
push r24
push r23
push r22
lds r24,cas1+3
push r24
lds r24,cas1+2
push r24
lds r24,cas1+1
push r24
lds r24,cas1
push r24
ldi r24,lo8(.LC0)
ldi r25,hi8(.LC0)
push r25
push r24
call printf
in r24,__SP_L__
in r25,__SP_H__
adiw r24,12
in __tmp_reg__,__SREG__
cli
out __SP_H__,r25
out __SREG__,__tmp_reg__
out __SP_L__,r24
ldi r25,0
ldi r24,0
/* epilogue start */
ret
.size main, .-main
.global c
.data
.type c, @object
.size c, 2
c:
.word 3
.global b
.type b, @object
.size b, 2
b:
.word 2
.global a
.type a, @object
.size a, 2
a:
.word 1
.comm cas2,4,1
.comm cas1,4,1
.ident "GCC: (Homebrew AVR GCC 9.3.0_3) 9.3.0"
.global __do_copy_data
.global __do_clear_bss
Na řádcích 26 až 31 dojde k načtení hodnot v proměnných a, b, c, do registrů.
Na řádcích 32 až 37 se hodnoty v registrech posčítají a uloží do registru, kde je právě uchována hodnota a.
Tím jsme vlastně dokončili první průchod cyklem.
Na řádcích 38 a 39 se uloží hodnoty 15 a 39 do registrů r22 a r23. K čemu to je? Když na nižší byte 16 bit hodnoty dáme hodnotu 15 (= 00001111 binárně) a na vyšší byte dáme hodnotu 39 (= 00100111 binárně), získáme 0010011100001111, což je dekadických 9999. Už tušíte, kam vítr vane? Na řádcích 32 až 37 jsme odbyli první průchod cyklem a zbývá nám ještě 9999. Reálně ale cyklem nemusíme procházet! Součet b + c je v našem případě neměnný. Stačí ho 9999 přičíst k hodnotě v registru s hodnotou proměnné a.
Cyklus kompilátor tedy zoptimalizoval do podoby a = a + b + c + 9999 * (b + c)
a=1, b=2, c=3
a = 1 + 2 + 3 + 9999*(2+3)
a = 50001
K čemu tedy došlo v případě kódu od pana Tesaře?
P. Tesař zmiňuje, že čas je stejný, bez ohledu na to, jestli je cyklus v kódu přítomen, nebo ne. Podle mě totiž dochází ještě k jedné optimalizaci v dalších fázích přípravy strojového kódu.
Můžete si všimnout, že hodnoty všech proměnných jsou známé již v době kompilace (viz předchozí rovnice). Po odstranění cyklu tak kompilátor mohl přistoupit rovnou k tomu, že výpočet v cyklu vyřešil v době kompilace!
Doufám, že vám článek trochu nastínil, co se při kompilaci může dít. (Ne)souhlasíte? Dejte vědět v komentářích 🙂